A Silly and Unscientific Survey of Internet Charsets
This data comes from a simple perl script (thanks Andre!), which read through all 32,000+ newsgroups on my ISP's server (thanks Chris!) and counted up each of the unique "charset=" tags that it found in the message headers.
I needed this data for an appendix that I am writing for Volume 2 of my O'Reilly book series, and couldn't find anything like it anywhere. So I begged and whined for the tools and access to a quiet server, and did it myself.
Hopefully somebody like Google Groups or SuperNews will pick up on this project and make click-through charts that show charset distribution per-hierarchy, per-group, and so forth. They will have better tools and better servers, and the Internet community would thank them for it.
What the heck is the charset stuff anyway?
RFC 2046—one of the MIME standards—define a "Content-Type" header which defines the packaging of the data being provided (some of the more common content-type headers are for "TEXT/HTML" and "TEXT/PLAIN"). One of the defined parameters for this header is the "charset=" parameter, which cumulatively defines the coded character set and character encoding scheme in use for textual data.
In short, the charset= tag is a MIME parameter which allows mailers to automatically adjust to the character set and encoding techinque used by the message sender. For example, the "Content-Type: TEXT/PLAIN; charset=US-ASCII" header tells the mail reader that the message body consists of good-ole seven-bit ASCII characters in a plain-brown text file, while "charset=ISO-2022-JP" indicates that the message contains a mixture of ASCII, Katakana, Kanji and other characters from the JIS X 0208 specification, some of which are encoded as single-byte septets, some of which are encoded as double-byte septets.
For the multilingual, international Internet, this is an extremely important service. There are thousands of different charsets in use throughout the far corners of the world, and being able to recognize and understand just what was being typed is an extremely important function.
The raw, untreated data
You can download the raw data as either an Excel 95 spreadsheet (no virus macros in Office 95), or as a CSV file (no summary data). If you just want to look at the pretty pictures, scroll down.
4,024,487 messages were processed over a period which spanned 73 hours and 23 minutes (over my 1.5Mb DSL line). Of the four million messages sampled, 3,389,401 had no charset defined. The remaining discussion in the following sections covers the charsets which were found.
Note that I did not include the undefined messages in my numbers below. Although it may seem that the lack of a defined charset implies US-ASCII, this is not necessarily the case. There are many international newsgroups which use behavior (as in, you showed up) instead of headers to determine the charset in use (see the Chinese and Korean newsgroups, most of the messages there have no headers, and they sure aren't ASCII). In the end, it was better to ignore the undefined headers.
Charset legality
All of the charsets were first examined for problems with the perl parser. The reported charsets were then compared to the IANA charset registry for legality.
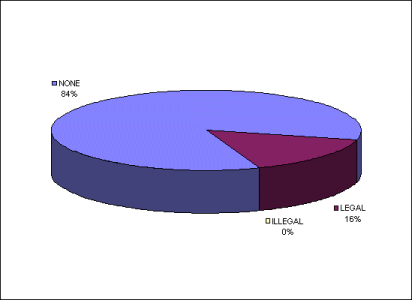
The perl script had some minor parsing problems, so I had to consolidate some of the numbers (I didn't want to fix the errors and restart, hey I already said this was silly and unscientific). Note that I tried to be flexible in this; "iso-8859-1>" looked like a parsing problem so I cleared it, while "is0-8859-1" (using zero instead of the letter "o") was obviously a sender error.
Of the four million plus messages, only 2,406 (approximately .05%) had illegal charsets defined. Of those, most of the typos were constrained to 10 or fewer posts, indicating operator error. The most common of the illegal charsets was "x-user-defined" (1317 posts), which is probably a machine-generated header crafted by a confused gateway or news server.
There are also a couple of interesting charsets which are technically illegal, but that is only because they have not been registered with IANA. For example, "Windows-874" showed up twice, and it is a Microsoft codepage charset for Vietnamese which Microsoft has not registered with IANA. Also, the "ks_c_5601" charset showed up 5 times, but it is not a registered alias for "ks_c_5601-1987", although "ksc_5601" is (this suggests a typo in the registration database).
This low error rate is good news for the Internet at large. Conformance is the norm. The low (16%) utilization of the charset= parameter is not great news, but it is better than nothing.
The most popular charsets
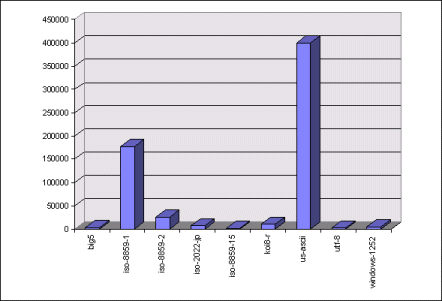
In order to figure out which charsets I need to worry about for my book, I looked at all of those charsets which had more than 1000 hits.
The most popular charsets are:
- Good-ole' seven-bit ASCII
- ISO-8859-1 is an eight-bit charset for Western European languages, including American English.
- ISO-8859-2 is an eight-bit charset for Central and Eastern European languages which use "Latin" characters (this excludes Cyrillic, Arabic, Hebrew, etc.)
- KOI8-R is an eight-bit charset used for Russian Cyrillic.
- ISO-2022-JP is a seven-bit, multi-byte charset which is popular for Japanese.
- Windows-1252 is an eight-bit "codepage" charset which is used by Windows 9x and up. It is almost identical to ISO-8859-1, except that it includes graphic characters in the control area. Part of the "embrace-and-extend" thing.
- BIG-5 is a favorite charset for Traditional Chinese.
- UTF-8 is an eight-bit, multiple-byte encoding used for Unicode and ISO-10646.
- ISO-8859-15 is an adjustment to ISO-8859-1, which includes the Euro currency symbol and some accented characters which are required for the French alphabet (but which were left out of ISO-8859-1).
Clearly, the Internet's Language of choice is English. We don't know what the next two or three dominant languages are because the ISO-8859-1 and ISO-8859-2 charsets are used by a number of different languages. Although this data is available through the "lang=" tag, I'm not repeating the study just to find out, since my book doesn't deal with language issues.
If more people would set their charset tags this dominance would likely shift.
The ISO distribution
I was surprised by the high return on the ISO-8859 charsets, and by the low number of people and mailers using Unicode. I keep hearing how "ISO-8859 is best for museums!" and other such noise which generally prefaces a glowing review of Unicode, so it was surprising to see how low the adoption rate really was.
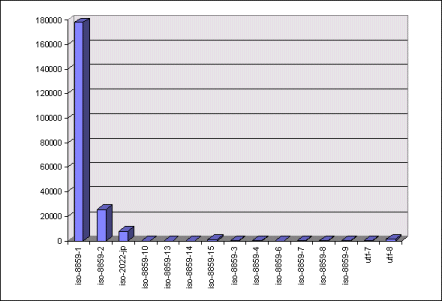
Below is a chart which breaks out the "ISO" charsets in closer detail. I include ISO-2022-JP in here even though this charset is not technically an ISO charset, although it is based on ISO standards, and it is a prime target for Unicode's promised functionality.
Unicode is in a solid fourth place position in the ISO hierarchy of internationally sanctioned and standardized charsets, with ISO-8859-15 coming up to meet it. Looks like the Unicode Consortium needs to do some end-user marketing. Perhaps once there are more Unicode-aware operating systems and applications deployed, this number will rise significantly.
Clearly, however, people are using charset tags, and this is good news. Hopefully somebody will pick up on this effort and began monitoring trends over periods of times. It would be nice to see how quickly the Internet is becoming an International medium instead of a US-centric one.
I would also like to see more vendors setting default charsets based on locale and other parameters if the user doesn't do it themselves.

Copyright © 2010-2017 Eric A. Hall.